Smart Documents
Introduction
Smart contracts promise to radically transform the way, speed, and cost of transactions, not only in the financial market but across the economy.
These technologies are at a relatively early stage of development. As a result, there is still a lack of consensus on what a smart contract is, what role it can play, and how it can interact with existing legal standards and documentation.
Could a smart contract fully replace an existing legal contract, or would it merely automate some or all of the actions specified in the contract?
Almost as important as this first question is how these contracts would be built and what technological tools and infrastructure would be needed to bring this new world to life.
To answer this, we will examine the types of smart contracts (smart contracts, automated documents, and ricardian contracts) and then explore different automation systems, with an emphasis on the Looplex architecture framework.
What are Smart Contracts?
Among the various competing definitions of a smart contract, two main schools of thought stand out: the view of computer scientists and the view of lawyers.
Neither side has the complete answer; in fact, they complement each other. Thus, we need to understand both perspectives to define what a “smart contract” truly is.
The terminology “smart contract” and “intelligent contract” is also the subject of philosophical debates. Here, we will use smart contract as a general term encompassing smart contracts, automated document contracts, and ricardian contracts.
More broadly, we will use the term smart document to define any content (including contracts) that contains the same computational attributes as a ricardian contract.

Lawyers and Programmers at Odds
The computer science community often uses the term “smart contract” in a way that is very different from how lawyers use it.
For lawyers, the term “contract” connotes a legal relationship of obligations and rights (content), while computer scientists tend to think of a smart contract in terms of the code that processes a transaction (execution).
For those who see the code as the most important element, a smart contract is software designed to perform certain tasks if predefined conditions are met.1
On the other hand, for those in the legal field dealing with the current (analog) legal infrastructure, the term refers more to the content than its execution. It’s a document—similar to paper in the previous technological paradigm—that expresses all the elements of a legally valid and binding contract, but in a digital medium and represented in code.
To be a true smart contract, both aspects are necessary: a digital representation of the content and the execution of the actions described within it.
In other words, it must (a) fall under the umbrella of a global relationship that creates legally binding rights and obligations, and (b) incorporate code designed to execute tasks when certain predefined conditions are met.
The “Contract” in a Smart Contract
For a contract to exist, be valid, and effective, our legal system imposes certain requirements. For example, in a sale transaction, three content elements must be satisfied: (a) an unequivocal declaration of the item (existing or future) being sold; (b) a defined or definable price, with terms and conditions for its payment; and (c) explicit manifestation of intent from both the seller and the buyer. As the Romans said: res, precium, consensus.
But that’s not all. Two additional elements are needed to express the contract in the real world: its form and registration. For instance, the sale of real estate must be done through a deed. And for some contracts, their effects (effectiveness) will only occur if the transaction is registered in a location defined by law: real estate registries, vehicle registries, corporate stock transfer books, etc.
For a smart contract to be a true contract, it must meet all these legal requirements, with some element of its execution being automated. If the code existed alone and did nothing, it would merely represent a different form of content without being a legally effective contract.2
”Intelligence” vs. “Smartness” of a Smart Contract
The use of the term smart in smart contracts refers to the fact that some element of the contract is automatic and self-executing according to predefined conditions. The contract itself can check whether certain states have occurred and, if so, trigger a predetermined action.
Demis Hassabis, co-founder of the artificial intelligence company DeepMind, states: “At its core, intelligence can be seen as a process that converts unstructured information into useful and actionable knowledge.”
However, a smart contract expressed solely in code does not possess this type of intelligence. All it does is execute pre-programmed steps. It is a purely algorithmic contract.
To go beyond mere “smartness” and become truly intelligent, a smart contract needs a nudge of human cognition, which participates in its contextual construction and expresses the intent to engage in the business represented within it.
At a minimum, humans indicate their expression of will, directly or indirectly (since it could be a contract triggering another); and at most, humans provide all the semantically relevant ingredients for its construction and execution. There are many variations in between.
Thus, smart contracts are more than smart contracts in the narrowly defined sense by computer scientists:
They are algorithms in code that instantiate execution through software agents.
They encapsulate the conversion of unstructured information into useful and actionable knowledge (structured data).
They represent a legally valid and enforceable contract, recognized by the current state legal system.
In other words, for a smart contract to be complete from the perspective of both law and computer science, it must have agency (runtime code performing tasks, not necessarily all of them), structured data (the output is machine-readable), and legal validity (it can be taken to court for enforcement in the event of human or machine default).
Types of Smart Contracts
The Perspective of Computer Scientists
Most applications that computer scientists call “smart contracts,” running on distributed networks such as Ethereum, are not truly smart contracts because they lack the third element of legal validity (enforceability). Instead, they rely on being “Turing complete”3 or, more narrowly, being entirely self-executing without human intervention.
Because they self-execute without human intervention, discussions about their legal validity and interaction with the judiciary become irrelevant. The application runs regardless of what the parties think or do after it starts. There is no breach of contract and no debate about the interpretation or scope of clauses or obligations.
Magical, right? The problem with this is that the practical implementation of a smart contract encounters the complexity and opacity of the legal system. Since nothing can be implied or referenced by context, the software agent must contain within its code a microcosm with all the necessary elements for its execution.4
Smart contracts are programmed using propositional logic.5 To maintain their self-sufficiency in execution, the use of predicate logic becomes prohibitively expensive to compute. It would require a complete semantic reference model of law embedded in the application, which is simply not feasible.6
As a result, these applications can only perform very simple operations, such as discrete purchase and sale of unambiguous items like simple securities without ancillary obligations, declarations, or guarantees. This severely limits the reach and utility of smart contracts.
The Perspective of Lawyers
One way to bypass the limitations of reproducing the full legal complexity of most contracts is simply not to tackle the problem!
Lawyers and other legal professionals can convert their legal content into a series of automated generation instructions in document assembly systems. This process is known as legal coding7.
These types of contracts or documents are called automated documents. Unlike the smart contracts of computer scientists, automated documents are fully valid from a legal perspective and are partially capable of generating structured data for reuse and BI but lack any agency.
Their output is static: a set of text, graphics, and tables that require humans to interpret and execute. Although the content may be abstracted, dramatically reducing the difficulty of formalizing knowledge, this solution lacks any understanding of the document’s content.
Essentially, it is a form-filler (similar to the previous field merge systems) with conditional logic, text formatters, and filters (data extraction from ERP, CRM, and other systems).

A Hybrid Approach: Ricardian Contracts
The concept of a ricardian contract was first introduced in 1995 by renowned programmer Ian Grigg, but the concept has since become part of the world of smart contracts, whether executed on blockchain or not. Here’s the basic definition:
A Ricardian contract is a type of digital document that serves as an agreement between two parties on the terms and conditions for an interaction. Its output is a legally valid document that can be read and executed simultaneously by both computer programs and humans.
The main difference from a smart contract is its legal validity within the infrastructure of the current legal system, as it includes a semantic layer in natural language expressing the agreement between the parties in the legal transaction.
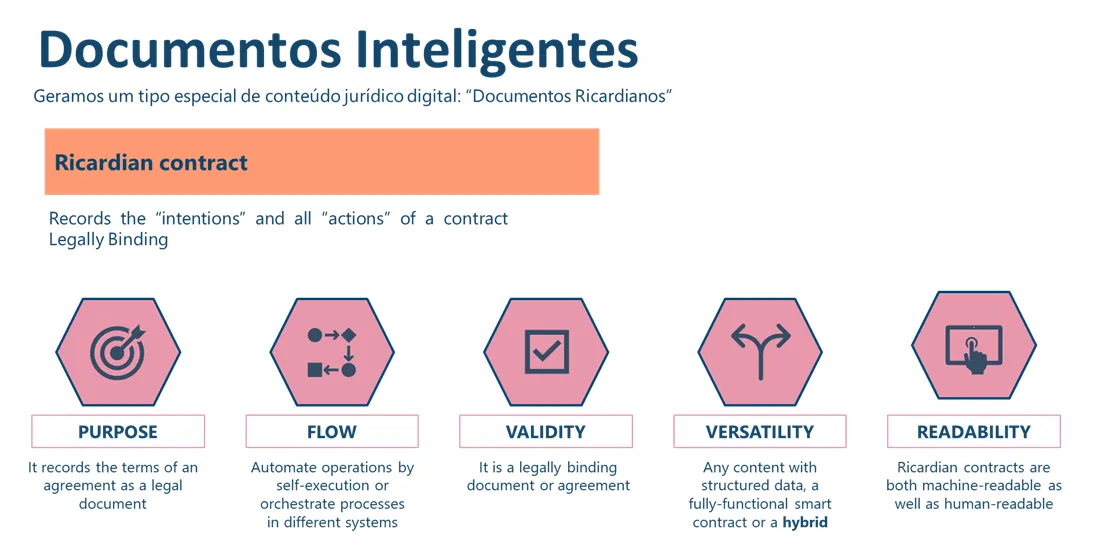
Additionally, unlike automated documents, a Ricardian contract captures structured data for analysis (like smart contracts), enables interaction with other systems and BI, and allows for the execution of methods and functions associated with its construction and the fulfillment of its obligations.
Simply put, it serves two purposes. First, it is a legally valid contract that is easy to read for the parties involved and their legal representatives. Second, it is a machine-readable and executable contract, capable of becoming a smart contract.
However, since it does not require self-execution without human intervention (in case of disputes, it can still be taken to court), the digital transformation process can be gradual, with Ricardian contracts behaving as mere automated documents at one end or as a Turing complete smart contract at the other.
Finally, this flexibility allows the solution to extend to other types of documents. Similar to automated documents, not only contracts but also petitions, decisions, memorandums, and other content can become Ricardian documents.
Automation Systems
Another aspect concerns the different capabilities of software systems that create, store, and execute smart documents.
We will divide them here into four different types, in ascending order of sophistication and functionality: field merge, document assembly, expert systems, and digital experience platforms (DXP).
Field Merge
Field merge (field fusion or field filling) is the oldest technology in this area. It was introduced by Microsoft in the early 2000s with the Mail Merge function used to generate letters, envelope labels, and other basic documents by merging data from an Excel document with a Word template.
Since field merging can only replace a variable in a document with the inserted value, it is only suitable for very basic documents that do not vary depending on the values entered. A good example of an appropriate use of field merging is address fields for letterheads, mail merge documents, or labels where language patterns, syntax, or formatting do not need to be adjusted based on the data values entered.

Document Assembly
Document assembly systems are an evolution of field merge. They allow you to program logic in the process of assembling your documents with conditional logic, formatting, and filters.
Thus, they include templates marked with variable fields and basic logical operations (decision trees), which use text segments and/or pre-existing data to assemble a new document from a user interview.
Expert System
In the field of artificial intelligence, an expert system is a computer system that emulates the decision-making ability of a human expert.
Expert Systems are designed to solve complex problems by reasoning through bodies of knowledge, represented mainly as IF-THEN rules in a separate layer instead of common procedural code.

An expert system is divided into subsystems or layers: it decouples the inference engine (rules engine) from the knowledge base (knowledge base). The knowledge base represents facts and rules, and the inference engine applies the rules to known facts to deduce new facts. Inference engines may also include explanation and debugging capabilities.
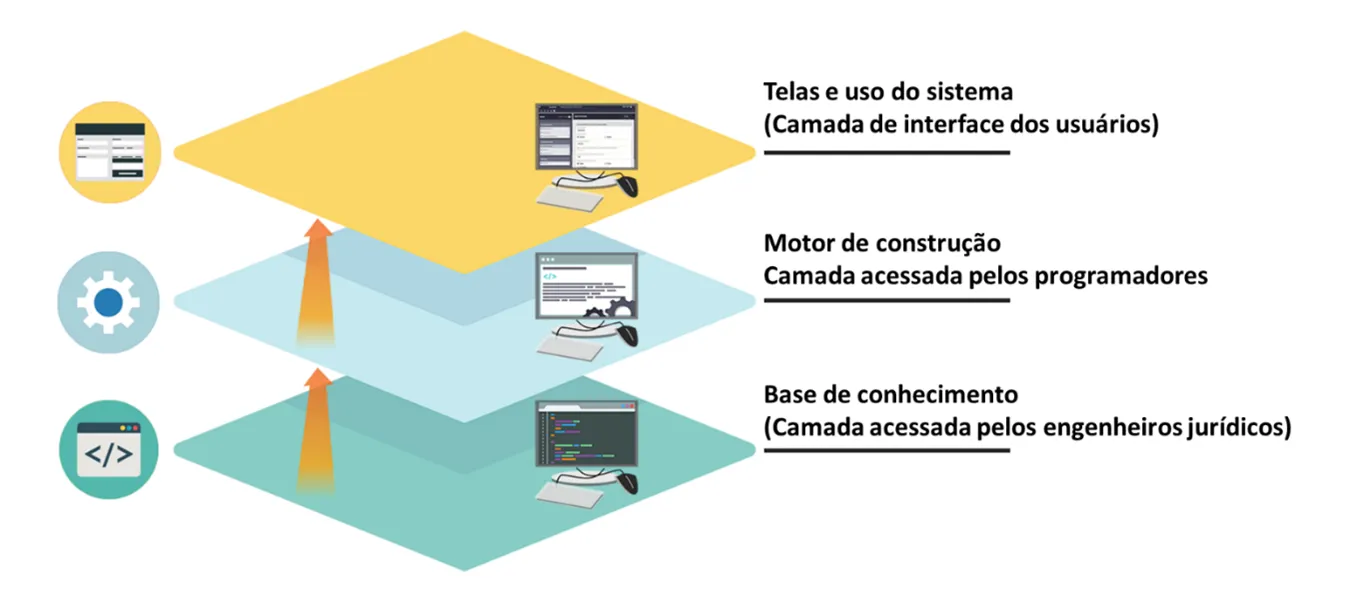
This decoupling of engine and knowledge base into different layers enables work specialization, with lawyer-programmers (legal engineers) focusing on content conversion, while computer scientists and software engineers focus on optimizing the platform’s execution infrastructure.
Additionally, in expert systems, it is possible to organize the knowledge base to use predicate logic, indicating complex semantic meaning to terms in natural language, and allowing the reuse of legal logic entities that have been previously normalized according to a Semantic Reference Model.
Digital Experience Platform
A Digital Experience Platform (DXP) is designed to manage, deliver, and optimize digital experiences consistently across all phases of the customer lifecycle.
In other words, a DXP is a collection of integrated products and services that help organizations deliver a consistent digital experience to their clients. Some of these products and services control what the user sees, while others work behind the scenes to collect and analyze data or to integrate systems together.8
Some of the main elements of a DXP are:
- A content management system (CMS)
- Project management and/or relationship management software (CRM/ERP)
- Embedded analytics and BI platforms
- Integrated business process automation systems (BPA)
- E-commerce or marketplace applications9
Looplex is a legal services DXP, where the Content Management System (CMS) element is actually a complete Expert System10, capable of generating both unnormalized legal content in its knowledge base (i.e., using propositional logic similar to that used in a document assembly system) and semantically referenced content in an ontological legal representation model.
Beyond databases segmented by services and specific contexts, all knowledge base content referenced in our Semantic Model is accessed by process automation agents (Looplex Flow BPA), ETL pipelines for Legal Analytics and BI, as well as a project management system (case management system), which is Looplex Cases.
Looplex is capable of generating Ricardian documents (not just contracts), thereby covering any demands for automated documents and even the generation of smart contracts.11
Additionally, other legal logic objects can be generated, decoupled but fully integrable with each other, composing a true network of mini smart contract or daemon applications capable of executing different aspects of a digital legal services experience. We call them Legal Applications.
“Headless” CMS (expert system)
In a traditional CMS, the same software system controls content management and processing on the backend and the interface presentation on the frontend.
However, modern CMS platforms are “headless” (dissociated). An integrated frontend solution is offered for all services, but clients can use all services directly via API or using web components to create their own experience or integrate one or more aspects of the platform into their own systems and services.
In our DXP, this is called Looplex Inside, and its access is provided through Looplex Graph, our integration gateway.
Conclusion
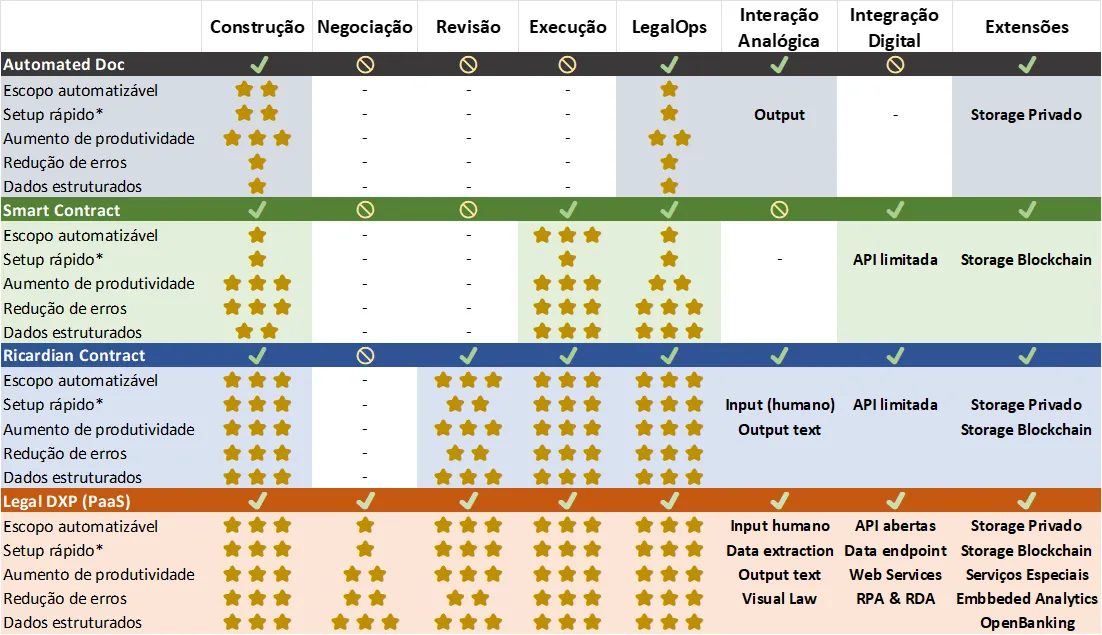
Summarizing the central ideas of this article into a consolidated table:
Footnotes
-
Such tasks are often incorporated and executed in a distributed ledger. For example, well-known implementations of smart contracts describe software agents that create utility tokens and cryptocurrency (DApp for ICO), provide an electronic voting mechanism (DAO), and offer a blind auction mechanism, among others. ↩
-
Take the example of a software agent formulated so that a predefined amount of an asset is moved from one person’s account (A) to another’s (B) if a pre-determined condition is met. This software agent does not create legal obligations between A and B. It does not impose a legal obligation on A to transfer the asset; the agent simply anticipates that a transfer will occur if the relevant condition is satisfied. If the software agent is designed to fulfill a pre-existing legal obligation, this would seem to be an instance where the code materializes a smart contract, as described earlier. However, this raises the question of why A would initiate such an agent if it did not satisfy a legal obligation to B, and what would happen if A simply decided not to execute the software agent. ↩
-
In the area of smart contract design, the use of this terminology is also not unanimous. Here, we adopt the perspective that Turing completeness refers to the ability of a smart contract to execute all the legal operations contained within it and thus finalize all acts related to a legal business without the need for any subsequent interpretation and/or human action. A highly simplified explanation of the issue can be found here: https://academy.binance.com/en/glossary/turing-complete ↩
-
Even when aided by Oracles to verify conditions and events or to define variables, all operations still need to be defined (declared) and their execution parameters pre-determined or determinable without human intervention. Reintroducing the need for human action at any point after the contract’s signing or emergence exposes its implementation to the risk of being illegitimately blocked. ↩
-
Programmers declare objects and establish elementary propositions, but their meanings are not analyzed to determine whether such propositions are true or false. You store the provisions of a contract as explicit rules. Even when adding deontic operators (permissions and obligations), smart contracts built this way lack any “knowledge” of the law or “understanding” of the meaning of the words used in the document. To understand the philosophical problem involved, see Ronald K. Stamper’s classic 1991 paper Semantics in Legal Expert Systems: https://ris.utwente.nl/ws/files/6690611/Stamper91role.pdf. ↩
-
In addition to the complexity of the code itself, which would have to be 100 or even 1,000 times larger than the code of a smart contract based on simple functions and propositional logic, the computational cost is high, and performance is reduced due to the need for the software agent to carry all the inputs (instantiated data objects), execute all functions, and perform logical operations in the same runtime environment. ↩
-
Legal coding is the process of taking a standard draft and adding syntax to it so that it can be properly automated in document assembly systems. Once a document is “coded,” the model (or template) can be used in document assembly systems to query information from a database and complete the task of batch document assembly with the appropriate and relevant information. ↩
-
See, for example, https://www.smoothfusion.com/blog/what-is-a-digital-experience-platform-dxp ↩
-
This module is not yet available on the Looplex platform. ↩
-
With two distinct inference engines (Looplex Assembler, Looplex Render), two visual analytics engines (PowerBI and Looplex Plot), and several other options depending on the automation challenge desired by the user. ↩
-
If the user actually needs a Turing complete smart contract, executable on a distributed ledger (DLT) such as Ethereum’s blockchain, it is possible to generate a dual-layer output: text and execution code for the content, without prejudice to the automated execution flows that can run within the platform. ↩