Looplex Semantic Reference Model
Legal engineers and developers need to understand the foundations of the Semantic Reference Model: Concepts and Taxonomies, Ontologies, and Data Modeling.
This document concludes with an explanation of how we implement the Looplex Semantic Reference Model.
Concepts and Taxonomies
The foundation of any Semantic Model contains the idea of concepts—definitions of terms that need to be or can be disclosed within a specific domain. Profit is a concept often disclosed in a business domain; similarly, obligation is a concept disclosed in a legal domain.
Concepts are more meaningful with a range of supporting information and enable the explicit creation of relationships between different concepts. Concepts are defined by—and referenced in—standards, rules, or legislation.
For instance, just as profit is what remains after expenses are deducted from revenue, a legal obligation (legalObligation) is “a bilateral, transient relationship that describes an action or transaction (legalTransaction) that one or more subjects (legalSubject) must perform and whose performance can be demanded by other subjects.”
The concept of an Obligation has various types or labels for different purposes. The main distinction is that types map conceptual variations of a concept, while labels only change the interface name (displayName) of an entity, leaving its semantic meaning unchanged.

Labels express the special or local meaning of a concept depending on its context. Labels typically appear in system-generated content interfaces, such as Word, PDF, or PowerPoint files that print contracts, petitions, or documents; webpages; data files sent via API to other systems; case sheets in Looplex or other management software; Excel spreadsheets; BI dashboards; and more.
Additionally, the same concept can have multiple labels in the same context to represent variations across different languages.
Collections of related concepts are contained in a taxonomy. Taxonomies are the framework of metadata against which information can be reported.
A taxonomy is thus a “vocabulary” or “dictionary” that can import a market-standard hierarchy and structure (e.g., ISO specifications, LEDES, IFRS, W3C, CVM, Basel III CRD IV banking reports, SUSEP insurance reporting frameworks, among others), legal doctrines, case law (e.g., the General Part of the Civil Code, GDPR), groupings of clients (companies and law firms dealing with real estate contracts), or specific clients (internal taxonomies of a company’s documents or workflows), enabling the exchange of legal or business information.
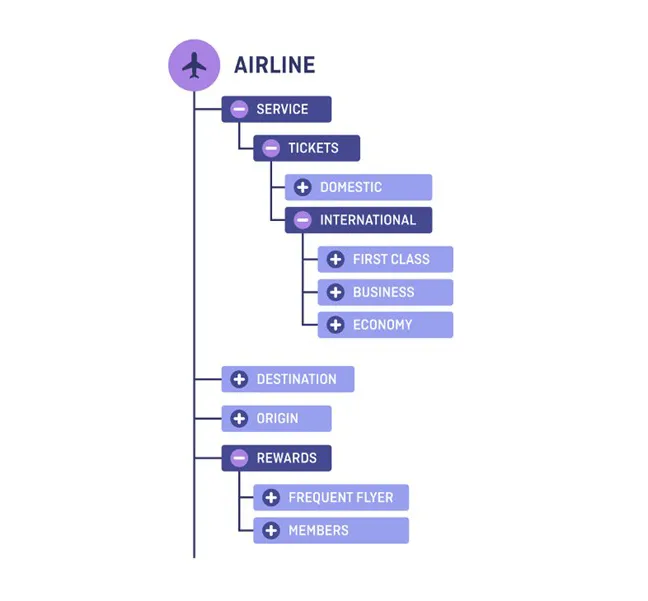
Examples of Taxonomy
Taxonomies of concepts form the first step in building a ontology.
Ontologies
An ontology is built from (a) a vocabulary of terms and their meanings (our concept taxonomy) and (b) their relationships, services, rules, and transactions.
An ontology is a formal specification providing fragmentable and reusable knowledge representation. Examples of ontologies include:
- Taxonomies
- Vocabularies
- Synonym or variation maps
- Topic maps
- Logical models
An ontology specification includes descriptions of domain concepts and properties, relationships between concepts, restrictions on how relationships can be used, and individuals as members of concepts.
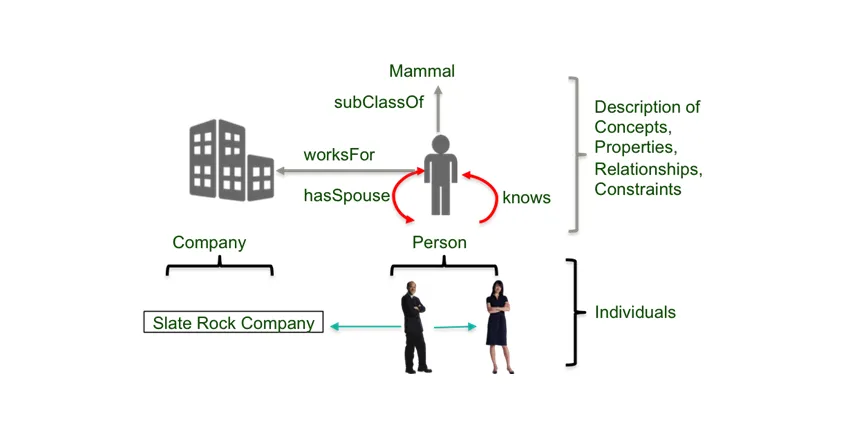
What are the benefits of using an ontology?
Ontologies are very useful for obtaining a shared understanding of legal knowledge and making assumptions explicit, supporting various activities.
Ontologies facilitate data integration for analysis (Legal Analytics and BI), apply domain knowledge to data (Common Data Model), support interoperability between systems, enable model-driven automated legal applications and content, reduce development time and cost, and improve data quality by enhancing metadata.
The Web Ontology Language (OWL) adds more powerful modeling capabilities to RDF and RDFS. It enables logical consistency checks, rule satisfaction checks, and classifications like instance type.
Ontologies also add equivalences and differences of identity (sameAs, differentFrom, equivalentClass, equivalentProperty), and more expressive class definitions such as class intersections, unions, complements, disjunctions, and cardinality restrictions.
Additionally, ontologies provide more expressive property definitions, such as object and datatype properties, transitive, functional, symmetric, and inverse properties, and value constraints.
Finally, ontologies allow creating repositories using semantic schemas and models (Common Data Model). This makes automated reasoning about data possible and easy to implement once the most essential relationships between concepts are incorporated into the ontology.
Data Modeling with RDF
The Resource Description Framework (RDF) is a graph data model formally describing the semantics or meaning of information. It represents metadata, or data about data.
RDF consists of triples based on the Entity-Attribute-Value (EAV) model, where the subject is the entity, the predicate is the attribute, and the object is the value. Each triple has a unique identifier called a Uniform Resource Identifier (URI), resembling webpage addresses. The subject, predicate, and object in a triple represent links in a network or graph.

For example, in “Fred hasSpouse Wilma,” Fred is the subject, hasSpouse is the predicate, and Wilma is the object. Similarly, in “Fred hasAge 25,” Fred is the subject, hasAge is the predicate, and 25 is the object.
Multiple triples connect to form an RDF model. The graph below describes characters and relationships from the Flintstones animated series. We can easily identify triples like “WilmaFlintstone livesIn Bedrock” or “FredFlintstone livesIn Bedrock.” We now know the Flintstones live in Bedrock, part of Cobblestone County in Prehistoric America.
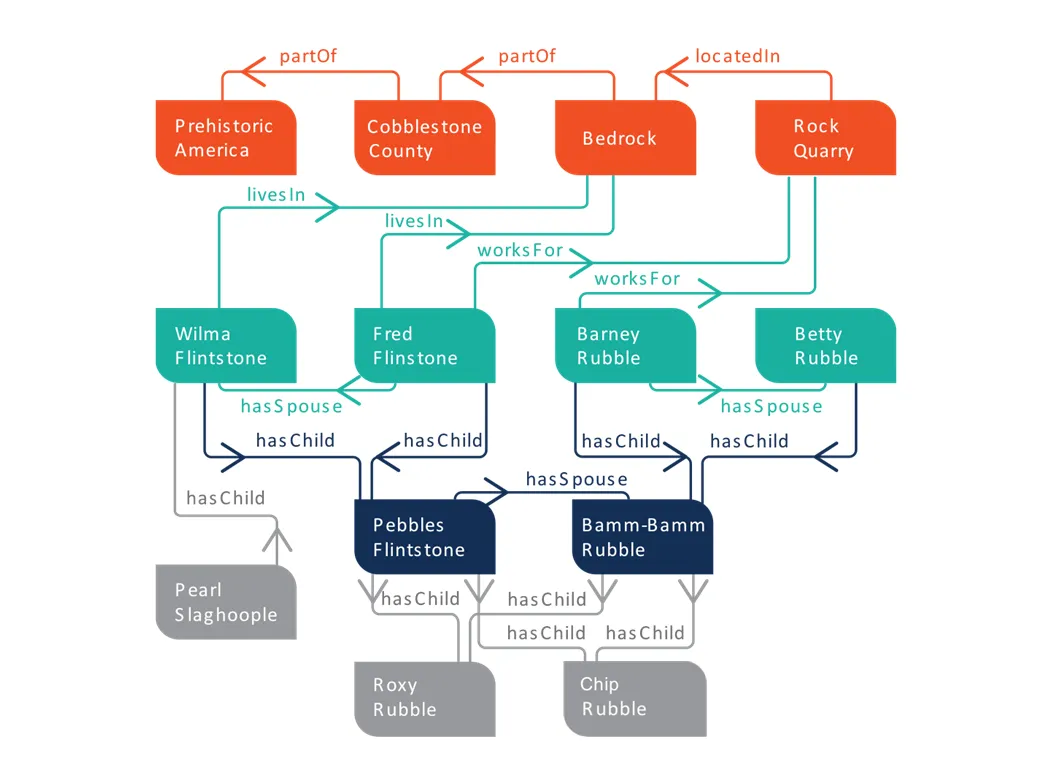
What is RDFS
The RDF Schema (RDFS) adds schema capabilities to RDF. It defines a metamodel of concepts like Resource, Class, and Datatype and relationships like subClassOf, subPropertyOf, domain, and range.
RDFS provides a means to define classes, properties, and relationships in an RDF model and organize these into hierarchies. It specifies rules or axioms for concepts and relationships, which can infer new triples.
Enterprise Knowledge Graph
Combining taxonomies, ontologies, and resource description frameworks (graph databases) creates a complete Enterprise Knowledge Graph.
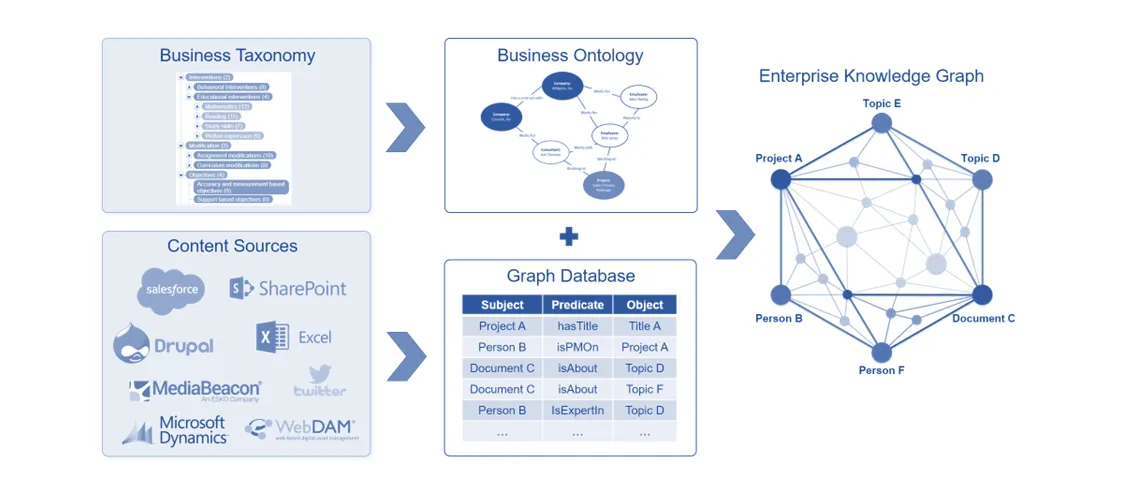
Enterprise Knowledge Graphs enable many functionalities and services in enterprise management systems. Looplex’s knowledge graph facilitates various intelligent applications on our platform, from contextual search to implementing sophisticated legal analytics models.

Looplex Semantic Reference Model Implementation
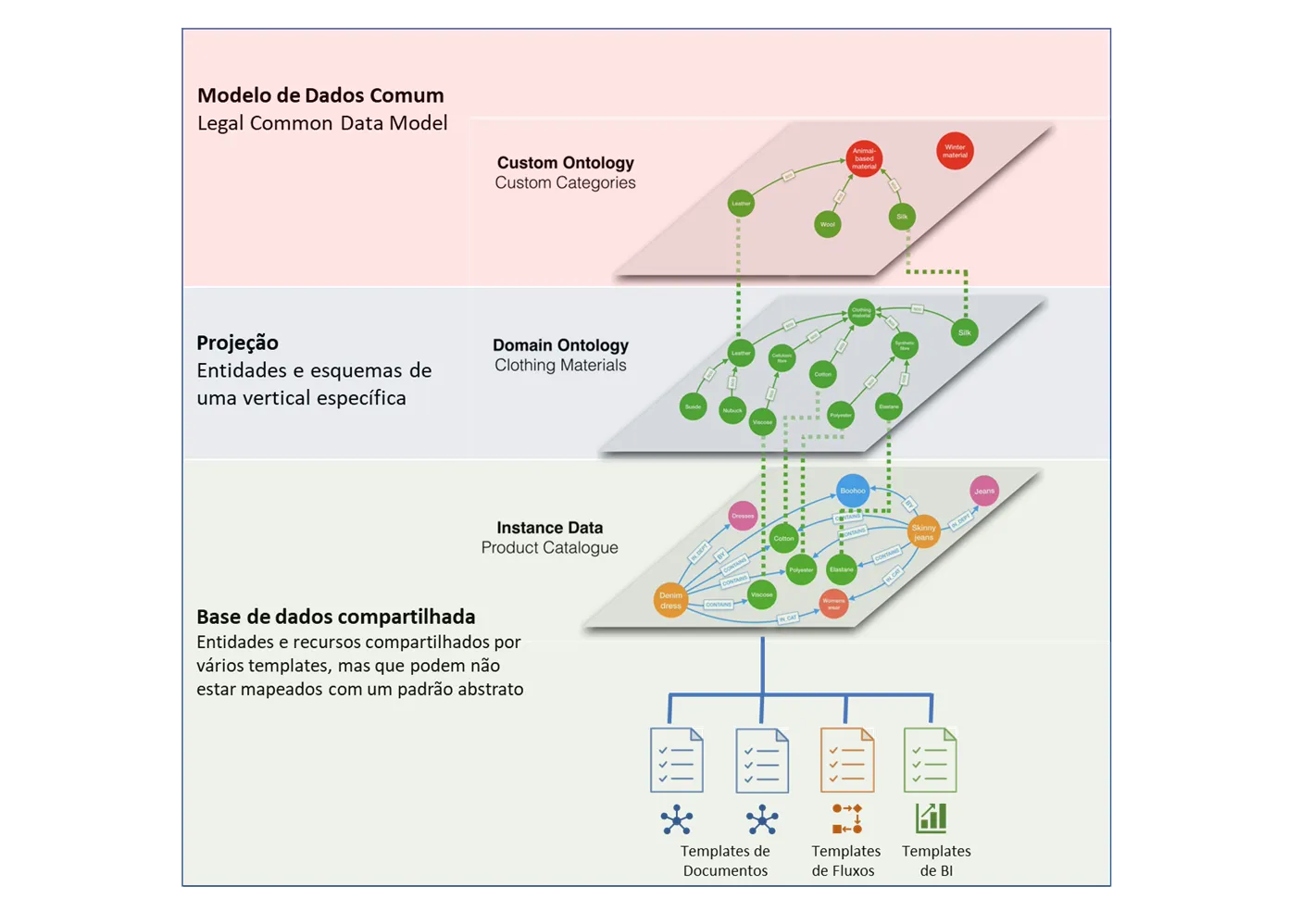
Looplex implemented a Semantic Reference Model accommodating multiple data layers, coexistence with unstructured or unmapped elements, and leveraging market models and standards while extending necessary elements for specific automation challenges.
1. Microsoft Common Data Model Extension
We adopted Microsoft’s Common Data Model (CDM), a collection of standardized, extensible data schemas published by Microsoft and its partners. This extensive list of pre-defined entities, attributes, semantic metadata, and relationships simplifies creating, aggregating, and analyzing data.
While CDM supports various verticals such as Sales, Healthcare, Marketing, and Finance, it lacks a legal vertical extension. The Looplex Legal Common Data Model extends Microsoft’s CDM for the legal domain, covering all concepts, entities, and structures.
2. Layered Standardization
The Looplex model allows progressive and incremental legal digital transformation through layered standardization:
- Base taxonomy: Derived from CDM, customizable for specific automation challenges (Projections).
- Projections: Customizations or extensions of logical entity definitions, influencing their resolution in the object model.
- Common usage: A final layer of shared data entities and elements unrelated to CDM or Projections.
This layered approach ensures that digital content can be automated even without full classification and abstraction of all entities, operations, and services.
3. Keeping Experts in the Process
We maintain human involvement for input processing, interpretation, analysis, or organizing workflows where unmapped elements exist. This approach enables 30–95% automation of legal content and services with 10–100x less mapping effort than full abstraction initiatives.
By supporting lawyers’ work and dramatically accelerating productivity, we focus on enhancing legal professionals rather than attempting to replace them, a strategy that has repeatedly failed in other legal tech initiatives.