Common Data Model
Gathering data from various legal documents across different cases is an expensive and time-consuming task. Without the ability to easily share and understand the same data, each Template1, each application2, and each data integration project becomes a completely custom and non-scalable implementation.
To address this, we created a common data model called the Legal Common Data Model.
The Legal Common Data Model (CDM) extends Microsoft’s Common Data Model and simplifies the process of integration, disambiguation, and reuse of legal data and entities by providing a shared data language for use in Document Templates, Tasks, Cases, BI Dashboards, and Cognitive Services.
Because we build these structures in a standardized way, our metadata system allows legal data and its meaning to be shared not only among documents, dashboards, and workflows on the Looplex platform but also among applications and other business processes formally integrated via Looplex Graph with Looplex.
In addition to uniform metadata, a common data model includes a set of extensible and standardized data schemas that comprise elements such as entities, attributes, semantic metadata, and relationships.
The Common Data Model contains a declarative specification and a definition of standard entities that represent concepts and activities commonly used by legal engineers in Templates, Cases, and Applications, while being extensible to observational and analytical data.
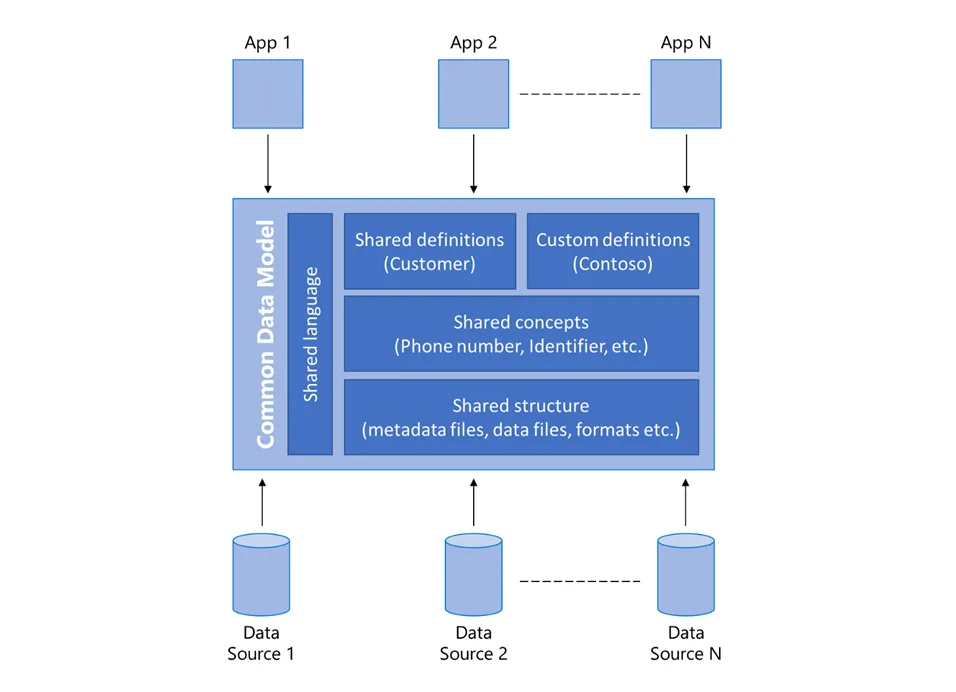
As all elements of the Common Data Model are defined, we can also develop methods to access and operate on this data in a way that all applications can use the same standardized procedures.
Why use the Common Data Model?
Imagine a legal engineer tasked with automating three different contracts. It is likely that each legal transaction was independently created by different lawyers with varying structures to represent the same entities, such as Parties or jurisdiction clauses.
These entities are almost (but not exactly) declared and operated in the same way. If you had used the Legal Common Data Model, you would have created your data in a standardized format (using the LDM’s standard entities, attributes, and relationships), allowing each Template to reuse the same data and structures.
Of course, each Template can have its own additional data and schemas, depending on the specifics of the particular case, but this should be the exception. When it comes to data development and exchange, we want other Templates, applications, and reports to quickly, cleanly (without noise), and reliably extract common data elements.
Thus, if you need to create a fourth Template or derive an existing implementation for a new client, for example, by merely extending a particular topic or adjusting the print layer, your data will be ready in the Legal Common Data Model schema. This allows development efforts to focus exclusively on the business logic and specific demands of the client’s case instead of getting bogged down in mapping all variables and transformations.
We have a design standard in our library to assess whether an element should be modeled, whether an existing Model should be customized, or whether it should be personalized.
Decoupling and Scalability
Historically, the work of coding a Template (in Lawtex or other languages) has been closely tied to creating a complete and self-contained architecture of a contract, petition, or document, with data mapping, declaration, and integration performed on a case-by-case basis.
The dissemination of knowledge within the community and even within Looplex’s internal legal engineering team was low, with little reuse of code or logic.
However, with the adoption of the Legal Common Data Model and all the services that support it, legal architecture and logic programming can occur independently, with a componentized and standardized content-building experience.
Other examples of team specialization and scalability made possible include:
-
Legal Data Engineering: Professionals handling Legal Analytics can access already curated data in their data pipeline, focusing only on necessary transformations. They can also release data for legal data analysts (who may work for clients) to manipulate data and create custom views in low-code or no-code platforms like Power BI.
-
Legal Process Engineering: Professionals creating flows and orchestrating processes can create their own automated business processes (Looplex Flows BPA) or release parameterizable processes for LegalOps analysts to implement flows using low-code or no-code tools like Flowable.
-
Application and Integration Development: Professionals bringing data from various Templates, Cases, and systems to make it accessible for use in other applications, such as a contingency and provisioning calculation service or integration with an external ERP or GED, all via standardized APIs.
The Looplex Legal Common Data Model simplifies data management and development, unifying all standardized or canonicalized data into a known format and applying structural and semantic consistency across all applications and deployments built according to the specification.
Benefits of L-CDM
- Structural and semantic consistency across applications and deployments
- Simplified integration and disambiguation of data collected from documents, processes, digital interactions, product telemetry, and person-to-person interactions
- Unified format, where data integrations can combine existing legal data with other sources and use these data holistically to develop applications and gain insights
- Ability to extend the Legal Common Data Model’s schema and standard entities to adapt models to specific legal business or client demands.
Canonization of Entities: Creating Models
In legal engineering, canonization (sometimes called standardization or normalization) is a process for converting data with more than one possible representation into a “standard,” “normal,” or canonical form.
This can be done to compare different representations of the same concept or analogous legal element (essentially texts in natural language), determine semantic equivalence (“this clause has the same meaning as this other one”), count and adjust the number of distinct data structures, improve the efficiency of various algorithms associated with the logical processing of that legal element, eliminate repeated or irrelevant variables, and even enable the imposition of meaningful ordering.
As Pontes de Miranda said, “legal systems are logical systems.” However, because legal transactions, disputes, and norms are all expressed in prose (natural language), they are subject to the same challenges as the Semantic Web: vastness, imprecision, uncertainty, inconsistency, and deception.
The process of canonization and modeling is part of our effort to transition from pure legal engineering to a model where legal architecture takes center stage:
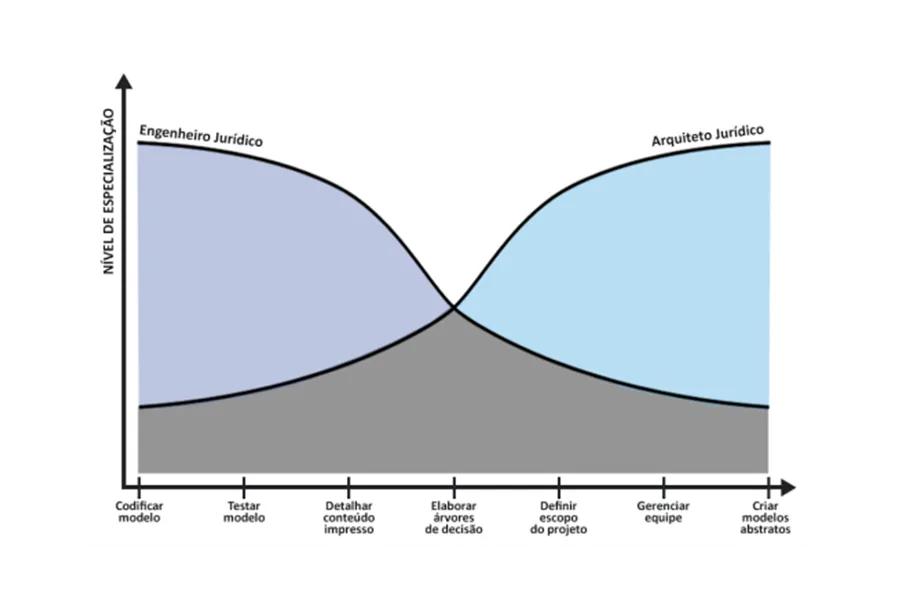
When a legal entity is canonized, it is labeled as equivalent to an existing Legal Data Model in the EJ Verse, or it can itself become a Model for that concept. Doing so gives Law—logical yet inherently artisanal—the precision and outcomes of computer science.
Extensions to the Legal Common Data Model
The Legal Common Data Model allows horizontal consistency for general legal data and entities, applicable to various types of legal business, which facilitates value creation from such data.
However, a substantial portion of legal content that can be digitized is specific to a particular type of legal business or dispute, meaning clients and partners need solutions and Template topics focused and tailored to their sector.
Additionally, there are numerous existing public data schemas and content repositories in use today.
Our Common Data Model includes a set of extensible and standardized data schemas derived from multiple sources, such as classifications from Schema.org, ISO, UTBMS and LEDES, IBGE, OAB, Dynamics365, Office365, and others. This collection of predefined schemas includes entities, attributes, semantic metadata, and relationships.
With this, we leverage schemas representing commonly used concepts and activities that can be even more easily shared with other applications outside the platform to simplify and standardize the process of digital conversion of legal content, such as creating, aggregating, and analyzing data processed by the platform during the digital experience journey for lawyers and users.
Looplex works closely with lawyers from various sectors to make the Legal Common Data Model more relevant to them by creating content accelerators in specific legal verticals that can be further customized and specialized.
What is a content accelerator?
Content accelerators take Looplex’s unified data approach one step further by speeding up the development of vertical solutions that use standardized data models specific to a legal area or economic sector, already integrated with business logic.
This allows clients and partners to easily create and parameterize any content specific to their sector in Templates, services, and applications running on the Looplex Platform.
Accelerators are fundamental components of the Looplex Platform, enabling law firms, legal departments, and other legal solution providers to quickly create vertical solutions for a sector.
Accelerators extend the Common Data Model to include new entities and support data schemas and concepts specific to sectors. They may appear as Projections of the Common Data Model or as a horizontal expansion of its entities.
Currently, Looplex is focused on providing, either directly or in partnership with the leaders and top experts in their fields, accelerators for the following sectors, with more to come:
- Labor litigation
- Civil banking litigation
- Insurance litigation
- Administrative litigation (Procon)
- Real estate contracts
- Pre-contracts (NDA, MOU, etc.)
- Powers of attorney
- Corporate acts of business corporations (LLCs and S.A.s)
- Due diligence reports for asset purchase operations
- Contract lifecycle management (CLM) for service providers
- SLAs and performance indicators for legal teams
- Mass litigation portfolio management
- Supplier contract portfolio management
- Economic group entity management

We continue to release new and updated accelerators for identified sectors. Check regularly for updates to our release plans and the list of the latest releases.